How to build a RAG application with Titan Takeoff Server

Welcome to the world of retrieval augmented generation (RAG) — a groundbreaking approach revolutionizing natural language processing applications. In the pursuit of creating more coherent, contextually relevant, and informative content, researchers have devised an innovative methodology that combines the prowess of retrieval-based techniques with the fluency of generative models. This combination enables machines to not only generate text but also retrieve and incorporate pertinent information from vast repositories, leading to a more refined, context-aware, and knowledgeable output. In this walkthrough, I hope to elucidate the techniques involved in building a RAG application, and provide a template to emulate for your own projects. As always, we at TitanML take away the tricky parts of initialising, building, optimising and orchestrating your models, so you can get straight into coding the application around them, prototyping your product and iterating on your big ideas.
So, what is RAG? Simply put, it is a technique for providing extra information to our models before expecting back an answer. This may be necessary because you want:
- it to answer questions based off of information outside of its knowledge base.
- to ask questions about events after the model's cutoff date.
- access to niche or specialised information (without the hassle of finetuning).
- or most commonly: you want the model to be able to inference about private data. Think medical records, emails, company docs and contracts, IP, anything internal that never had a chance to appear in the public internet scrape that went into the initial training.
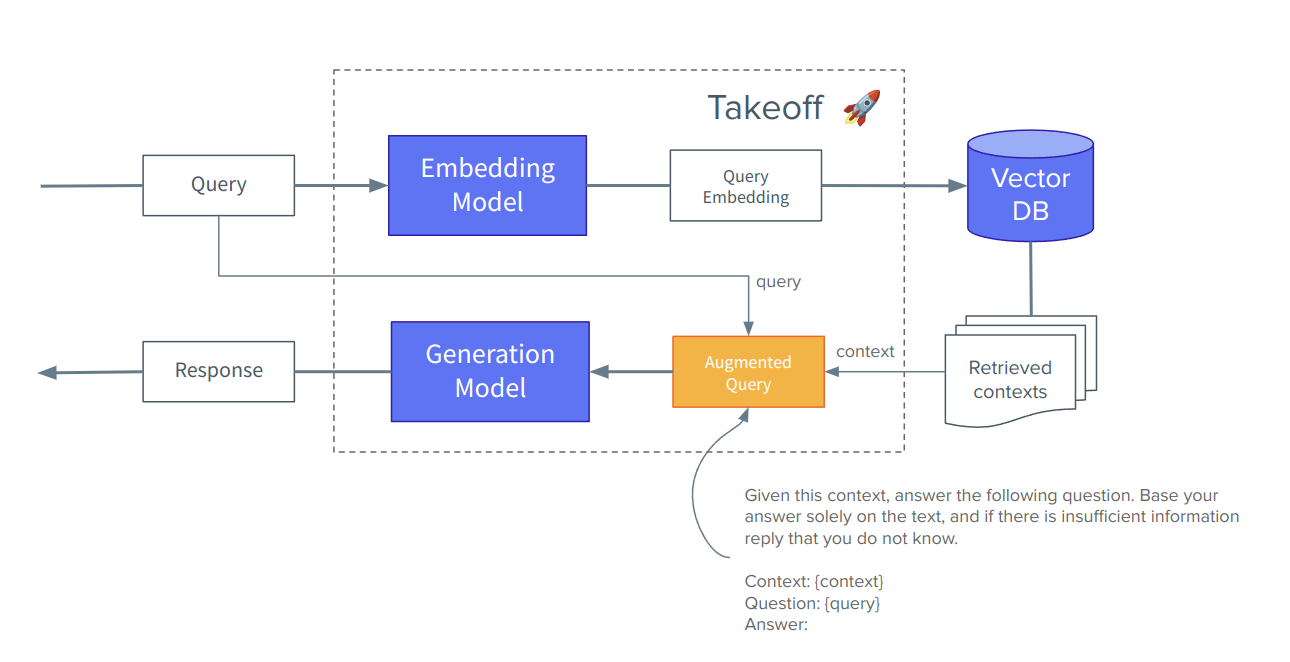
The idea behind RAG is to first go and collect the relevant bits of information from our large pool of documents and then add this text, hopefully containing the answer to the question, as an extension to our prompt of the generation model. Rather than make anything up, the model just has to read and extract the answer from the context provided. The way we can make comparison between texts and queries is based off of the idea of textual embeddings - if done well, similar text (words, sentences, sections or whole documents) should be embedded into similar vectors. We can then rank text matches between our query and passages using simple vector comparison maths, and hopefully receive high scores when the passage has similar content to what the question is alluding to.
Bank of Titan
For this demo we are switching industry - we are going to emulate a big bank with billions of assets under management - and importantly, our company information is split across a sea of distributed documents. For our application we need our chatbot to be able to retrieve and recall from these private documents, so the answers provided are correct, even though the corpus is not in the model's knowledge base.
documents = [
"Our research team has issued a comprehensive analysis of the current market trends. Please find the attached report for your review.",
"The board meeting is scheduled for next Monday at 2:00 PM. Please confirm your availability and agenda items by end of day.",
"Our quarterly earnings report will be released to the public on the 10th. Senior management is encouraged to prepare for potential investor inquiries.",
"The due diligence process for the potential merger with XYZ Corp is underway. Please provide any relevant data to the M&A team by Friday.",
"Please be informed that our compliance department has updated the trading policies. Ensure all employees are aware and compliant with the new regulations.",
"We're hosting a client seminar on investment strategies next week. Marketing will share the event details for promotion.",
"The credit risk assessment for ABC Corporation has been completed. Please review the report and advise on the lending decision.",
"Our quarterly earnings for the last quarter amounted to $3.5 million, exceeding expectations with a 12% increase in net profit compared to the same period last year.",
"The investment committee meeting will convene on Thursday to evaluate new opportunities in the emerging markets. Your insights are valuable.",
"Our asset management division is launching a new fund. Marketing will roll out the promotional campaign in coordination with the release.",
"An internal audit of our trading operations will commence next week. Please cooperate with the audit team and provide requested documents promptly.",
]
Titan Takeoff
For this demo, orchestration and inference of both models is going to be handled by a Takeoff Server. Our server runs inside Docker containers, so we can deploy and manage them from python using the docker-sdk. Reach out to us here to gain access to the Takeoff Pro image (all the SOTA features), or pull and build the community edition here and adapt your code accordingly.
TAKEOFF_IMAGE_BASE = 'tytn/takeoff-pro'
# Docker-sdk code
def is_takeoff_loading(server_url: str) -> bool:
try:
response = requests.get(server_url + "/healthz")
return not response.ok
except requests.exceptions.ConnectionError as e:
return True
def start_takeoff(name, model, backend, device, token=HF_TOKEN):
print(f"\nStarting server for {model} with {backend} on {device}...")
# Mount the cache directory to the container
volumes = [f"{Path.home()}/.takeoff_cache:/code/models"]
# Give the container access to the GPU
device_requests = [docker.types.DeviceRequest(count=-1, capabilities=[["gpu"]])] if device == "cuda" else None
client = docker.from_env()
image = f"{TAKEOFF_IMAGE_BASE}:0.5.0-{'gpu' if device == 'cuda' else 'cpu'}"
server_port = 4000
management_port = 4000 + 1
container = client.containers.run(
image,
detach=True,
environment={
"TAKEOFF_MAX_BATCH_SIZE": 10,
"TAKEOFF_BATCH_DURATION_MILLIS": 300,
"TAKEOFF_BACKEND": backend,
"TAKEOFF_DEVICE": device,
"TAKEOFF_MODEL_NAME": model,
"TAKEOFF_ACCESS_TOKEN": token,
},
name=name,
device_requests=device_requests,
volumes=volumes,
ports={"3000/tcp": server_port, "3001/tcp": management_port},
shm_size="4G",
)
server_url = f"http://localhost:{server_port}"
management_url = f"http://localhost:{management_port}"
for _ in range(10): # Give te server time to init and download models
if not is_takeoff_loading(server_url):
break
print("building...")
time.sleep(3)
print('server ready!')
return server_url, management_url
Our chatbot model:
chat_model = 'meta-llama/Llama-2-7b-chat-hf'
Starting Takeoff
takeoff_url, takeoff_mgmt = start_takeoff(
'rag-engine', #container name
chat_model, #model name
'compress-fast', #backend
'cuda' #device
)
# in terminal run: 'docker logs rag-engine' to see status
# first time running this may take a while as the image needs to be downloaded
Starting server for meta-llama/Llama-2-7b-chat-hf with compress-fast on cuda...
building...
building...
building...
server ready!
Let's check the status of our server
response = requests.get(takeoff_mgmt + '/reader_groups')
print(response.json())
{'primary': [{ 'reader_id': '68fc0c97',
'backend': 'awq',
'model_name': 'meta-llama/Llama-2-7b-chat-hf',
'model_type': 'CAUSAL',
'pids': [40]
}]
}
Takeoff streams generated tokens back from the server using Server Sent Events (SSE). These two utility functions help print the tokens in the response as they arrive.
def print_sse(chunk, previous_line_blank=False):
chunk = chunk.decode('utf-8')
text = chunk.split('data:')
if len(text) == 1:
return True
text = text[1]
if not previous_line_blank:
print('\n')
print(text, end='')
return False
def stream_response(response):
prev = True
for line in response.iter_lines():
prev = print_sse(line, prev)
Initial Result
We now have an inference server setup and ready to answer our queries, but with no RAG included - this means our model is going to have to wing it. Let's see how it does:
query = "What are our quarterly earnings?"
response = requests.post(takeoff_url + "/generate_stream",
json = {
'text': query
},
stream = True)
stream_response(response)
Our quarterly earnings are as follows:
Q1 (April-June)
Revenue: $100,000
Net Income: $20,000
Q2 (July-September)
Revenue: $120,000
Net Income: $30,000
Q3 (October-December)
...
Total Net Income: $100,000
Note: These are fictional earnings and are used for demonstration purposes only.
The model even admits itself that its answers are completely made up! This is good honesty, but also makes the generations absolutely useless to our production applications.
RAG
Let's help the model out by building the RAG extensions discussed at the beginning.
Adding an Embedding Model
I have chosen an embedding model that ranks highly on the HuggingFace Massive Text Embedding Benchmark leaderboard, and scores well for 'retrieval':
embedding_model = "BAAI/bge-large-en-v1.5"
# Add our embedding model to our Takeoff server
response = requests.post(takeoff_mgmt + '/reader',
json = {
'model_name': embedding_model,
'device': 'cpu',
'backend': 'baseline',
'consumer_group': 'embed'
})
print(response.json())
{ 'model_name': 'BAAI/bge-large-en-v1.5',
'device': 'cpu',
'consumer_group': 'embed',
'redis_host': None,
'backend': 'baseline',
'access_token': None,
'log_level': None,
'cuda_visible_devices': None,
'reader_id': None
}
Now when we request the status of our server, we should see both models present, ready for action:
# Check if model is ready and in its own consumer group
response = requests.get(takeoff_mgmt + '/reader_groups')
print(response.json())
{'primary': [{ 'reader_id': '68fc0c97',
'backend': 'awq',
'model_name': 'meta-llama/Llama-2-7b-chat-hf',
'model_type': 'CAUSAL',
'pids': [40]}],
'embed': [{ 'reader_id': 'd5faf2ec',
'backend': 'hf',
'model_name': 'BAAI/bge-large-en-v1.5',
'model_type': 'EMBEDDING',
'pids': [120]
}]
}
Minimal Vector Database
Vector databases are specialized databases designed for handling and storing high-dimensional data points, often used in machine learning, geospatial applications, and recommendation systems. They organize information in a way that enables quick similarity searches and efficient retrieval of similar data points based on their mathematical representations, known as vectors, rather than traditional indexing methods used in relational databases. This architecture allows for swift computations of distances and similarities between vectors, facilitating tasks like recommendation algorithms or spatial queries.
One of the essential pieces of a RAG engine is the vector database, for storing and easy access to our text embeddings. It is an exciting space, and there are a number of options to pick from out in the ecosystem (Dedicated vector database solutions: Milvus, Weaviate, Pinecone. Classic databases with vector search functionality: PostgreSQL, OpenSearch, Cassandra). However, for this demo we don't need all the bells and whistles, so we're going to make our own minimal one right here, with all the functionality we need. The VectorDB in our app sits external to takeoff, so feel free to swap in/out and customise to fit your personal VectorDB solution.
Our VectorDB needs a place to store our embedding vectors and our texts; as well as two functions: one to add a vector/text pair (we track their colocation by shared index) and one to retrieve k documents based off 'closeness' to a query embedding. The interfaces to our DB take in the vectors directly so we can seperate this from our inference server, but feel free to place the calls to the models via Takeoff within the VectorDB class.
class VectorDB():
def __init__(self, device='cpu'):
self.vectors = torch.tensor([]).to(device)
self.text = []
self.device = device
def add(self, vector, text):
if isinstance(vector, list):
vector = torch.tensor(vector)
vector = vector.to(self.device)
self.vectors = torch.cat([self.vectors, vector.unsqueeze(0)])
self.text.append(text)
def query(self, vector, k=1):
if isinstance(vector, list):
vector = torch.tensor(vector)
vector = vector.to(self.device)
distances = torch.nn.CosineSimilarity(dim=1)(self.vectors, vector)
indices = torch.argsort(distances,).flip(0)[:k].tolist()
return [self.text[i] for i in indices]
def stats(self):
return {'vectors': self.vectors.shape, 'text': len(self.text)}
db = VectorDB()
We can now populate our makeshift database. To do so, we send our text in batches to the embedding endpoint in our Takeoff server to receive their respective embeddings to be stored together. This example uses a conservative batch size to matcch our small demo - but feel free to tune to your own needs.
batch_size = 3
for i in range(0, len(documents), batch_size):
end = min(i + batch_size, len(documents))
print(f"Processing {i} to {end - 1}...")
batch = documents[i:end]
response = requests.post(takeoff_url + '/embed',
json = {
'text': batch,
'consumer_group': 'embed'
})
embeddings = response.json()['result']
print(f"Received {len(embeddings)} embeddings")
for embedding, text in zip(embeddings, batch):
db.add(embedding, text)
db.stats()
Processing 0 to 2...
Received 3 embeddings
Processing 3 to 5...
Received 3 embeddings
Processing 6 to 8...
Received 3 embeddings
Processing 9 to 10...
Received 2 embeddings
{'vectors': torch.Size([11, 1024]), 'text': 11}
For each of our 11 documents, we have a (1, 1024) vector representation stored.
Improved Results
Let's quickly remind ourselves of our original query:
print(query)
What are our quarterly earnings?
This is the first part of our new RAG workflow: embed our query and use our db to match the most relevant documents:
response = requests.post(takeoff_url + "/embed",
json = {
'text': query,
'consumer_group': 'embed'
})
query_embedding = response.json()['result']
# Retrieve top k=3 most similar documents from our store
contexts = db.query(query_embedding, k=3)
print(contexts)
['Our quarterly earnings report will be released to the public on the 10th. Senior management is encouraged to prepare for potential investor inquiries.',
'The investment committee meeting will convene on Thursday to evaluate new opportunities in the emerging markets. Your insights are valuable.',
'Our quarterly earnings for the last quarter amounted to $3.5 million, exceeding expectations with a 12% increase in net profit compared to the same period last year.']
Augmented Query
With this extra information, let's see if our model can provide the correct answer:
context = "\n".join(contexts)
augmented_query = f"context: {context}\n be as precise in your answer as possible, just give the answer from the context\nquery: {query}?\nanswer:"
response = requests.post(takeoff_url + "/generate",
json={ 'text': augmented_query}
)
answer = response.json()['text']
print(answer)
$3.5 million
Success!
Unified
def get_contexts(question, db, k=5):
response = requests.post(takeoff_url + '/embed',
json = {
'text': question,
'consumer_group': 'embed'
})
question_embedding = response.json()['result']
return db.query(question_embedding, k=k)
def make_query(question, context):
user_prompt = f"context: {context}\n be as precise in your answer as possible, just give the answer from the context\nquestion: {question}\nanswer:"
return requests.post(takeoff_url + '/generate_stream', json={'text': user_prompt}, stream=True)
def ask_question(question):
contexts = get_contexts(question, db, k=5)
contexts = "\n".join(reversed(contexts)) # reversed so most relevant context closer to question
return make_query(question, contexts)
stream_response(ask_question("what is the research team working on?"))
The research team is working on a comprehensive analysis of the current market trends.
Demo
queries = ["Which corporation is doing our credit risk assessment?",
"what is the research team working on?",
"when is the board meeting?"]
for query in queries:
print(f"Question: {query}")
stream_response(ask_question(query))
print("\n=======================================================")
Question: Which corporation is doing our credit risk assessment?
ABC Corporation.
=======================================================
Question: what is the research team working on?
The research team is working on a comprehensive analysis of the current market trends.
=======================================================
Question: when is the board meeting?
Monday at 2:00 PM.
=======================================================
And that is it! We have an end-to-end application that is capable of interpreting and then answering detailed questions based off of our private, internal data. The beauty of RAG is that we get the perks of generative models: we can interface our application with human language, and our model understands and adapts to the nuances and intentions of our question phrasing, and the model can explain and reason its answer; plus, we get the benefits of retrieval models: we can be confident that the answer is correct, based on context, has a source, and is not an infamous hallucination. In fact, as more and more people start bringing generative models into their products, RAG workflows are rapidly becoming the de facto way to design an application around the model at the core.
While the landscape of model deployment and orchestration can be challenging, the integration of two interdependent models may seem like an added layer of complexity. Luckily, TitanML is here to help - our expertise lies in managing these intricacies, so you can focus on your application and accelerate your product development.
Happy hacking!
About TitanML
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Our flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.